I implemented the RLHF algorithm from Deep reinforcement learning from human preferences, Christiano et.al. 2017.
I used a simple gridworld instead of the robotics environment in the paper.
RLHF has three components: An RL agent, a reward model and a human interface.
The three components are running simultaneously, with a circular information flow:
The RL agent samples 2 trajectories based on disagreement between reward models, and sends it to the human interface.
The human interface sends the user's preference to the reward model.
The reward model adds the user's preference to its training dataset. And forwards updated model weights to the RL agent.
Each component runs in its own process to enable true concurrency with python.
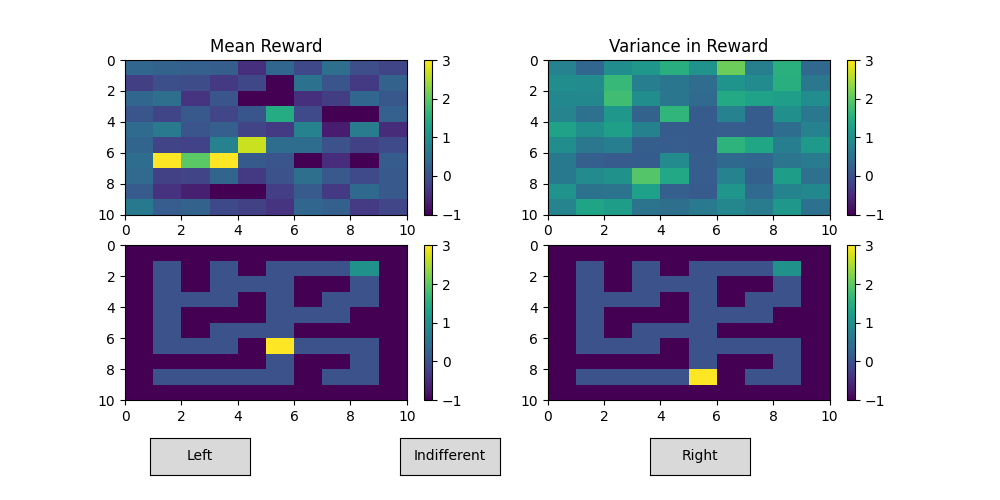
The picture below is the human interface after a while of me rewarding the agent to go straight left after starting in
the middle.
You can see that path going straight left is highly rewarded, and some other paths are punished with negative reward.
The variance between reward models is also lower in the middle, than on the edges.
The code can be found here.